
数据结构与算法(三)—— 线性表的应用
循环链表
循环链表的合并
1 | LinkList Connect(LinkList Ta,LinkList Tb){ //传入两个循环链表的尾指针,本操作为返回一个新表,故无需使用引用类型(&)进行传参 |
双向链表
双向链表的定义
1 | typedef struct DuLNode{ |
双向链表的插入
1 | int ListInsert_Dul(DuLinkList &L,int i,ElemType e){ |
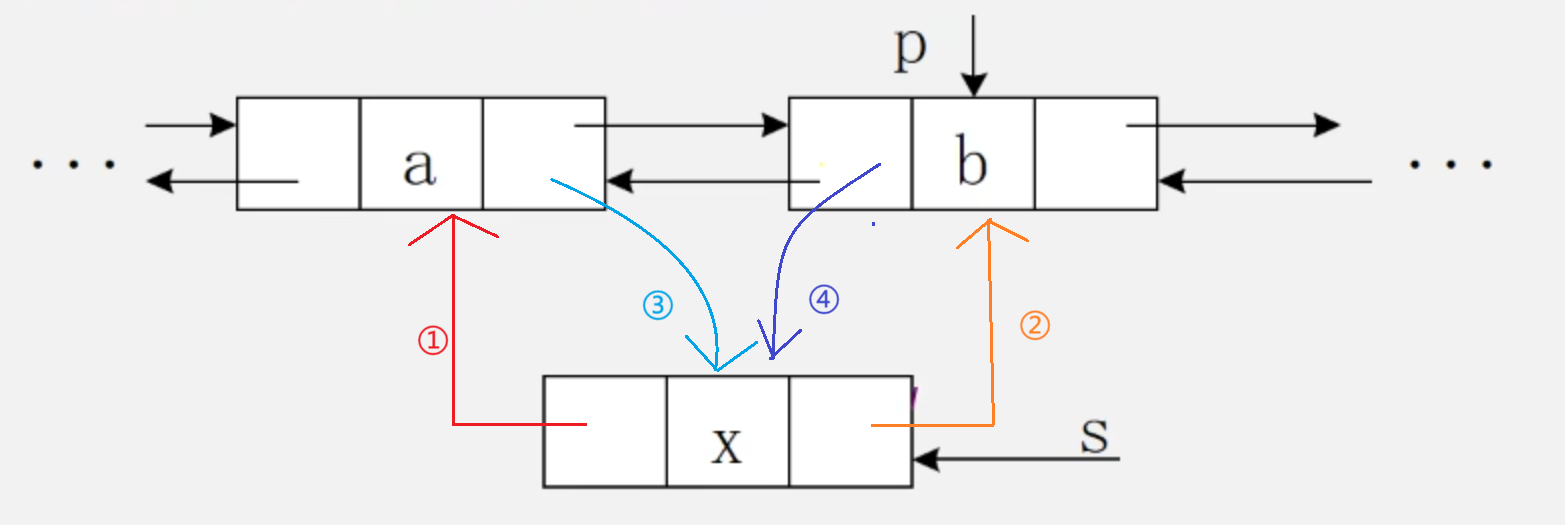
双向链表的删除
1 | int ListDelete_DuL(DuLinkList &L,int i,ElemType &e){ |
单链表、循环链表和双向链表的时间效率比较
| 查找表头结点(首元结点) | 查找表尾结点 | 查找结点*P的前驱结点 | |
|---|---|---|---|
| 带头结点的单链表L | L -> next 时间复杂度O(1) |
从L -> next依次向后遍历 时间复杂度O(n) |
通过p -> next无法找到其前驱 |
| 带头结点的仅设头指针L的循环单链表 | L -> next 时间复杂度O(1) |
从L -> next依次向后遍历 时间复杂度O(n) |
通过p -> next可以找到其前驱 时间复杂度O(n) |
| 带头结点的仅设尾指针R的循环单链表 | R -> next -> next 时间复杂度O(1) |
R 时间复杂度O(1) |
通过p -> next可以找到其前驱 时间复杂度O(n) |
| 带头结点的双向循环链表L | L -> next 时间复杂度O(1) |
L -> prior 时间复杂度O(1) |
通过p -> prior 时间复杂度O(1) |
顺序表和链表的比较
链表的优缺点
优点:
- 结点空间可以动态申请和释放
- 插入和删除时不需要移动数据元素
缺点:
- 存储密度小,每个结点的指针域会占用额外的存储空间
- $存储密度 = \frac{结点数据本身占用的空间}{结点占用的空间总量}$(即$\frac{数据域所占空间}{数据域所占空间+指针域所占空间}$)(顺序表的存储密度为1)
- 链式存储结构是非随机存取结构,对任一结点的操作都要从头指针依指针链查找到该节点
适用情况
- 表长变化较大
- 频繁进行插入或删除操作
顺序表的优缺点
优点:
- 存储密度为1,不用为表示结点间逻辑结构增加而外的存储开销
- 随机存取,按位置访问元素的时间复杂度为O(1)
缺点:
- 结点空间预先分配,可能会导致闲置或溢出
- 插入和删除时平均约移动表中一半元素,时间复杂度O(n)
适用情况
- 表长变化不大,且能事先确定变化范围
- 很少进行插入或删除操作,经常按元素位置序号访问数据元素
线性表的应用
线性表的合并(将Lb表插入到La表后)
1 | void union(List &La,List &Lb){ |
算法的时间复杂度为:O(ListLength(La) * ListLength(Lb))
有序表的合并(顺序表实现)
1 | void MergeList_Sq(SqList LA,SqList LB,SqList &LC){ |
有序表的合并(链表实现)
1 | void MergeList_L(LinkList LA,LinkList LB,LinkList &LC){ |
综合应用案例
稀疏多项式的运算(完整实现)
1 | typedef struct PNode{ |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 HaruYuki's Blog!
相关推荐

2025-02-09
数据结构与算法(四)—— 栈和队列
数据结构笔记目录:数据结构与算法(一)—— 线性表的顺序表示及常用操作数据结构与算法(二)—— 线性表的链式表示及常用操作数据结构与算法(三)—— 线性表的应用数据结构与算法(四)—— 栈和队列数据结构与算法(五)—— 串、数组和广义表数据结构与算法(六)—— 数和二叉树 栈与队列的应用实例出栈顺序 条件: 进栈时允许出栈 解题思路: 向上进行时可以跳跃,向下进行时不可以出现跳跃 Ex:1某栈的输入序列为a,b,c,d,下面的四个序列中,不可能为其输出序列的是()A.a,b,c,d B.c,b,d,a C.d,c,a,b D.a,c,b,d 进制转换:倒取n/d的余数(d为进制数)EX:2:取...

2025-02-23
数据结构与算法(五)—— 串、数组和广义表
数据结构笔记目录:数据结构与算法(一)—— 线性表的顺序表示及常用操作数据结构与算法(二)—— 线性表的链式表示及常用操作数据结构与算法(三)—— 线性表的应用数据结构与算法(四)—— 栈和队列数据结构与算法(五)—— 串、数组和广义表数据结构与算法(六)—— 数和二叉树 串的模式匹配:BF算法串的定义12345#define max_Size 100typedef struct{ char *ch; int length;}SString; DF算法1234567891011121314int index_BF(SString A,SString B){ int i = 1;int j = 1; while(i <= A.length && j <= B.length){ //条件1:主串走到结尾。条件2:完全匹配,匹配串走到结尾 if(A.ch[i] == B.ch[j]){ i++;j++; } else{ i = i - (j-1) +1;...

2025-03-04
数据结构与算法(六)—— 数和二叉树
数据结构笔记目录:数据结构与算法(一)—— 线性表的顺序表示及常用操作数据结构与算法(二)—— 线性表的链式表示及常用操作数据结构与算法(三)—— 线性表的应用数据结构与算法(四)—— 栈和队列数据结构与算法(五)—— 串、数组和广义表数据结构与算法(六)—— 数和二叉树 树的相关定义 根节点:非空树中无前驱结点的结点 结点的度:结点拥有的子树数量 树的度:树内各节点的最大度 叶子:度等于零的终端节点 孩子与双亲:结点的子树的根称为该结点的孩子,该结点称为孩子的双亲 祖先:从根到该结点所经分支上的所有结点 有序树:将树中每个结点的各子树看成是从左到右有次序的(即不能互换) 无序树:将树中每个结点的各子树从左到右是没有次序的(即可以互换) 二叉树的性质 在二叉树的第i层上至多有$2^{i-1}$个结点 深度为k的二叉树至多有$2^{k}-1$个结点 对于任何一颗二叉树T,如果其叶子数为$n_{0}$,度为2的结点数为$n_{2}$,则$n_{0} = n_{2} +1$对于完全二叉树: 具有n个结点的完全二叉树的深度为$\lfloor log_2(n)...

2025-01-13
数据结构与算法(二)—— 线性表的链式表示及常用操作
数据结构笔记目录:数据结构与算法(一)—— 线性表的顺序表示及常用操作数据结构与算法(二)—— 线性表的链式表示及常用操作数据结构与算法(三)—— 线性表的应用数据结构与算法(四)—— 栈和队列数据结构与算法(五)—— 串、数组和广义表数据结构与算法(六)—— 数和二叉树 单链表的表示123456789typedef struct Lnode{ ElemType data; struct Lnode* next;}Lnode,*LinkList; //LinkList为指向结构体Lnode的指针类型//定义链表LinkList L;//定义节点指针pLNode* p;//LinkList == LNode*,分开两种定义方式的目的是使定义更加清晰 Ex:1:存储学生信息的单链表123456typedef struct student{ char nom[12]; //学号数据域 char name[8]; //姓名数据域 int score; //学生成绩数据域 struct student* next;...

2025-01-13
数据结构与算法(一)—— 线性表的顺序表示及常用操作
数据结构笔记目录:数据结构与算法(一)—— 线性表的顺序表示及常用操作数据结构与算法(二)—— 线性表的链式表示及常用操作数据结构与算法(三)—— 线性表的应用数据结构与算法(四)—— 栈和队列数据结构与算法(五)—— 串、数组和广义表数据结构与算法(六)—— 数和二叉树 顺序表的构建12345#define max_Size 100typedef struct{ ElemType elem[max_Size]; int length;//当前长度}SqList; Ex:112345678910#define max_Size 100 //宏定义最大长度typedef struct{ char ISBN[20]; char name[50]; float price;}Book;typedef struct SqList{ Book* add;//存储空间基地址 int...

2025-02-02
稀疏多项式的运算非伪码完整实现
伪码描述过于抽象,于是决定自己动手按照逻辑实现一次。看到AC的时候实在是太过激动,于是决定另开一篇文章分享一下实现源码。代码写的及其的不美观,要是能再精简一下就好了 12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273747576777879808182838485868788#include <iostream>using namespace std;typedef struct PNode{float coef; //系数int expn; //指数struct PNode* next; //指针域}PNode,*Polynomal;void MergeList_L(Polynomal LA,Polynomal LB,Polynomal &LC){ PNode* p = LA ->...

